Experiments
Experiment Results
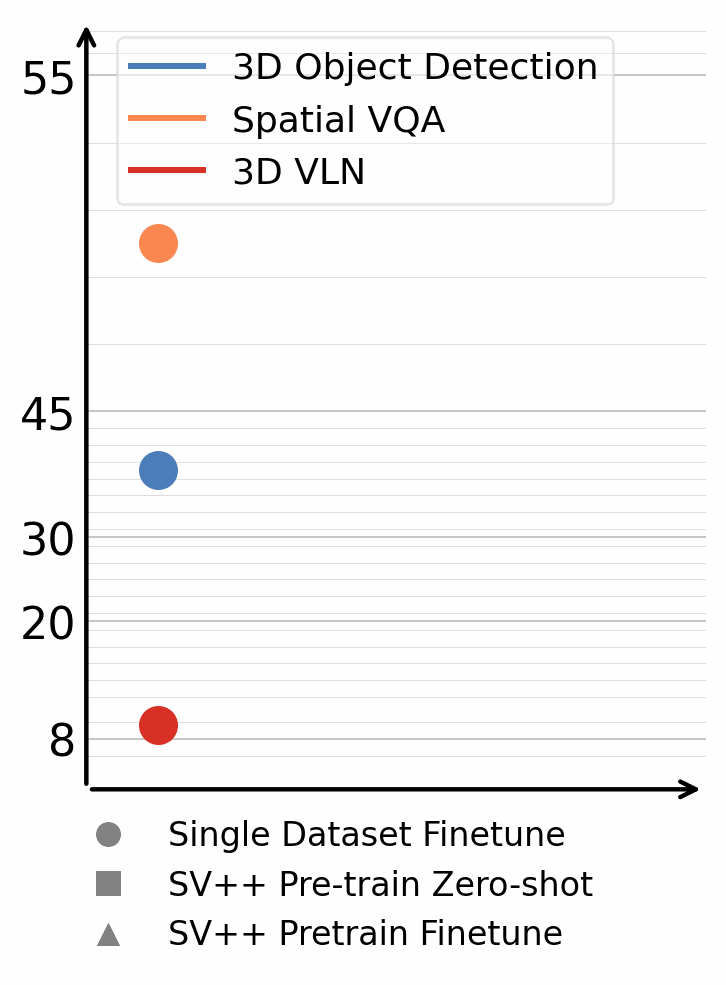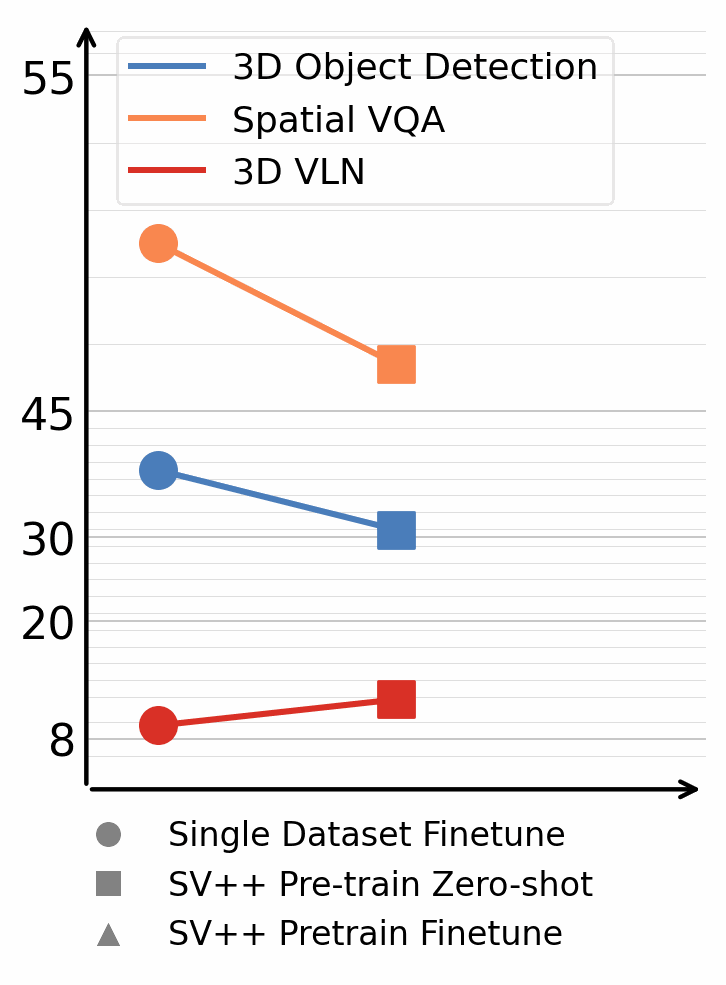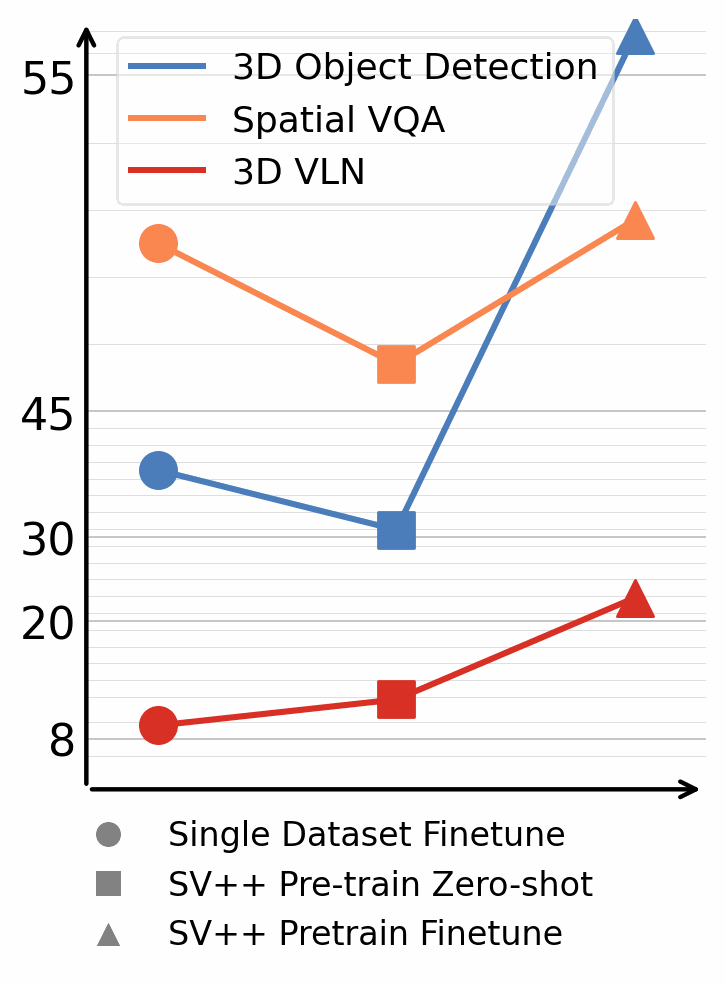
3D Detection & Segmentation
Models trained on SceneVerse++ achieve strong zero-shot performance on ScanNet and ARKitScenes, and further significantly improve after finetuning (+20.6 F1@0.25).
3D Spatial VQA
Training on SceneVerse++ significantly improves the spatial reasoning performance of Vision-Language Models, achieving zero-shot performance comparable to models trained on ground-truth 3D scenes.
3D Vision-Language Navigation
From real-world videos to simulated navigation, SceneVerse++ brings an extra 14% navigation success rate after finetuning.